This is the third and most comprehensive part about handling errors and exceptions in C#. Here are the first and the second part. Also, you can take a look at the blog post about global exceptions handling in WPF applications.
Errors Handling and many other topics you’ll find in my new video course “API in C#: The Best Practices of Design and Implementation”. Take it with 60% discount! Also, nothing can stop you from reading further)))
The problem of errors handling is really an old one. Despite that, I feel a lack of sources which aggregate the information and reveal all the problems relate to exceptions.
The first question which immediately comes to mind is “Why we need to understand how to properly handle errors?” There are at least two reasons:
- Do not piss out the users. I know too many applications which fail without even telling the user what went wrong;
- There is a category of applications which are very errors-sensitive. These are the applications which deal with huge financial
You can open any book on C# and see that for handling (or representing) any unfortunate situations such as validation fails, the critical system fails authors suggest to use exceptions.
The topic is a little bit holy war because there are no silver bullets, but it doesn’t mean that we don’t want to understand the problems which accompany exceptions using.
Several years ago, I asked Uncle Bob about the problems of using exceptions and he replied:
Use exceptions. They are much cleaner than all the other options.
The fear about uncaught exceptions is misplaced. Forgetting to catch an exception is much better than forgetting the if statement to check a result. The former fails visibly and the latter fails silently.
The fear of messy code near the try/catch blocks is also misplaced. Use the ‘extract till you drop’ rule, and make sure that any function with a try/catch block has _only_ the try/catch block in it; with the try block being a single function call.
Finally, write tests for all your exception throws, and all your exception catches. Error processing is part of the legitimate behavior of your system and testing it is very important.
At that moment, I didn’t have enough expertise to initiate any meaningful debates, so I just accepted Uncle Bob’s reply. Only after a couple of years, I realized that there are no any other developers who love exceptions as much as Uncle Bob. I’m joking, but there is a shard of truth in every joke.
Let’s look at what Eric Lippert and Anders Hejlsberg said about exceptions to lay the foundations of understanding the problems which accompany them.
Checked Exceptions
There was an interesting talk between Anders Hejlsberg, Bill Venners, and Bruce Eckel in 2003 sometime after the .NET 1.1 release.
In short, among other matters, Anders acknowledged that the practice of using checked exceptions failed in java because of versioning and scalability problems. For those, who are unaware of what checked exceptions are, I’ll remind that checked exceptions are exceptions that a method may raise and they are a part of the method’s signature. For instance, if a method might throw an IOException, it must declare this fact explicitly in its method signature. In the following code snippet, you can see a function which declares that it may throw the IOException.
[code lang=”java”]
public static void readFile(string filePath) throws IOException {
FileReader file = new FileReader(filePath);
BufferedReader fileInput = new BufferedReader(file);
// Print first 3 lines of the file
for (int counter = 0; counter < 3; counter++)
System.out.println(fileInput.readLine());
fileInput.close();
}
[/code]
A client function which calls a function with declared checked exceptions should contain inside its body corresponding catch blocks or include them in its own signature.
So, what are the versioning and scalability problems?
Small HelloWorld programs look very good with checked exceptions, but in large applications arise functions which contains a chain of calls to external services and in the end, we have functions which declare too many exceptions in their signatures. It becomes a problem because no one wants to handle ten different exception types.
The second problem concerns versioning. The thing is that you can’t just add another one exception type into a signature in the API which is already in use by many clients since it will be a breaking change; clients must be rewritten considering added exception types.
Hejlsberg said that they didn’t have any approaches greater than existing ones, so they just decided to leave checked exceptions aside. So now we’re living with unchecked exceptions in the world of .NET.
Eric Lippert (a former developer of the C# compiler) said that exceptions from the control flow point of view are goto statements without even a label. I’ll quote Eric Lippert:
Their power comes at an extremely high cost; it becomes impossible to understand the flow of the program using only local analysis; the whole program must be understood. This is especially true when you mix exceptions with more exotic control flows like event-driven or asynchronous programming. Avoid, avoid, avoid; use exceptions only in the most exceptional circumstances, where the benefits outweigh the costs.
And how to live with that? Hejlsberg in that old talk said that in a well-written program the ratio between try-catch and try-finally expressions is roughly 1 to 10. So, in finally blocks we just release acquired resources and handle exceptions globally. We don’t want to catch exceptions here and there all over the code base.
Well, I’d say that Anders encourages the “catch-them-all” approach regarding the exceptions handling strategy since you can’t write meaningful handling logic in global exception handlers. The only thing we can do with exceptions at the highest point in the stack is either to swallow them or to let a program to fail fast.
Use Case
Let’s consider a super-simple use case. Let’s say we need to read a file on a disk. Also, we have a requirement to not fail in the case something goes wrong with the attempt to read a file since we have many other features in the application and it can continue to execute. So, we call the File.ReadAllLines at some point. An innocent call.
What exceptions types so we need to handle to satisfy our requirements? If we go to MSDN and look at the list of possible exceptions from that call, we will see the following:
- ArgumentException,
- ArgumentNullException,
- PathTooLongException
- NotSupportedException
- DirectoryNotFoundException
- IOException
- FileNotFoundException
- UnauthorizedAccessException
- SecurityException
Everything is clear with the first four exception types. If we face one of these types, it means that we have a bug in our program because we violated the preconditions of the called function. So, the only one thing we can do is to fix the bug.
Concerning IOException, FileNotFoundException and DirectoryNotFound exception we can say that actually, the latter two are the derivatives of the IOException. Despite, the IOException may be thrown as well.
The last block is comprised of the Unauthorized and Security exceptions. These are, well, exceptions connected with security problems regarding the file access.
To sum up, following “the best practices” we have to catch from 3 to 5 exception types (we can either catch only the IOException or all three types, plus two security exceptions) depending on the requirements of the concrete application.
This is not the worst case; I bet there are tons of BCL calls which potentially may throw 10 different exception types.
All in all, I want to mention that I’ve never ever seen any programmers who consciously read the documentation for each call and then really handle all the possible exception types. But let’s pretend that we handle all these exception types we mentioned, does it mean that from that moment no disgusting exceptions will be thrown sneaking in the application, avoiding all our catch-blocks?
The funny thing is that actually, we can’t be sure in that it will not happen. There are no people who can correctly document all the possible exception types which potentially may be thrown from literally any BCL call. So, if we catch only the known exception types, 99% of calls will be successful and 1% will fail because of exotic exceptions. In order to deepen our understanding of the exception problems, let’s dig a little bit deeper. Let’s look at the problem of exceptions raised from the unmanaged code. This may help us to make our programs more reliable in certain circumstances.
Corrupted State Exception (CSE)
There is the SEHException type, for instance. When managed code drills down to unmanaged code (it can be any WinAPI call) inside of which an exception is raised, CLR tries to map that exception into a known .NET exception type. In case CLR fails to do that, it wraps the information about the exception from unmanaged code into the special SEHException type and throws it. After that everything as usual, if an application doesn’t catch that SEHException, it crashes.
SEHException belongs to the category of exceptions named Corrupted State Exception (CSE in short). AccessViolationException also belongs to this category of exceptions. The CLR team discussed whether it is sane to give the opportunity for managed code to handle CSE or not. The problem is that CSE usually points out on the system context problem, hence such problems should be handled only by the code which is acquainted with that context.
Beginning from the .NET 4.0, by default, CSE can’t be caught by the standard try-catch block. Although, there are two ways to catch them. Before looking at that ways, let’s talk about should we handle CSE and when we might want to do that.
Why, when and how to catch CSE
Generally, we can’t write any meaningful compensational logic handling CSEs. As a rule of thumb, such exceptions are caused either by bugs in unmanaged code or corruptions at the system level.
Personally, I faced the case when from the same call to a COM-component the SEHException was thrown. Seemingly, that component was buggy, but we haven’t access to its source code and we can’t avoid using it. I had to suppress that SEHException since the practice has shown that everything is fine after suppressing and after some time that buggy function started to work properly.
Thus, I can say that the only case when we want to handle a CSE is when there are no other ways to fix the problem and at the same time we need our application to continue running. I doubt that you’ll ever get 100% sure that there are no problems after suppressing CSE, so the only thing which can help is the thorough integration testing.
There are two ways to catch a CSE.
- Add the [HandleProcessCorruptedStateException] attribute to the method which wants to catch a CSE.
- Set a special “legacyCorruptedStateExceptionsPolicy” to true in the app.config file. It allows to catch CSE everywhere in the code base.
So, I want, to sum up, saying that the probability of an application’s failure depends on the number of users and the aggressiveness degree of the environment in which a program is running. This is just the reality.
Okay, I hope now you understand what the problems accompany those bloody exceptions. Let’s talk a little bit about the common exception handling strategies.
Three common exceptions handling strategies
We have three common ways of dealing with exceptions:
- catching only those exceptions about the rising possibility of which we know for sure. E.g. we read about them in the documentation.
[code lang=”csharp”]
try {
File.ReadAllLines();
}
catch (IOException ex) {}
//are you sure we didn’t forget to catch other exception types?
[/code] - catching all the exceptions with the following strategy:
- catch all the exceptions we are aware of and which we actually can handle properly
- fail if we face an exception from the list of critical exceptions
- swallow all the types which do not fit the first two points.
Example:
[code lang=”csharp”]
try {
File.ReadAllLines();
}
catch (Exception ex) {
//delegate the handling process
ExceptionManager.HandleException(ex, “Policy”);
}
[/code] - and the last one – catching all the exceptions without any analysis.
[code lang=”csharp”]
try {
File.ReadAllLines();
}
//I don’t care!
catch (Exception ex) {}
[/code]
I hope you understand now that there is no a silver bullet. Each approach has some advantages as well as drawbacks.
The first one is the way of the samurai. Supposedly, this is the hardest way from the perspectives of reaching a decent level of code reliability. As I’ve already mentioned, people often fall with this approach into the situation when they should add new catch-blocks from time to time in places where they were unaware of certain types of exceptions.
The second approach is based on the filtration. Typically, there is exception handling mini-framework behind this approach which allows you to create exception handling policies. In a policy, we can define exception types which we want to handle, attach handlers, define a list of critical exceptions which we don’t want to catch and so on. You can define as many policies as you like. So there can be several policies for typical cases like reading a file from a disk, connecting to a database and so on. Such policies are supported by for example the Exception Handling Block in the Microsoft Enterprise Library framework. Seemingly, this is the most moderate approach, it allows to rely on the supple strategy implemented in an object-oriented way.
The third way, “catch them all” is a head-on approach. It’s a temptation to put balls on all that difficult stuff connected with the proper handling of errors and exceptions.
Sometimes it can be a reliable and sufficient for success strategy to just catch all exceptions. In my opinion, as always in engineering, we can’t just blindly state that “we should never ever write try{}catch(Exception ex){}“. In my opinion, you should reason about your errors and exceptions handling strategy when you start developing a new application, bearing in mind a couple of things:
- What sort of application are you going to develop? Is it a nuclear weapon managing software? Is it software for a device intended to struggle with cancer? Is it a cardboard game? Is it a notepad-like app? Obviously, requirements for reliability are different for such applications.
- What is the proficiency level of your team? Are you sure, that your team is ready to deal with proper errors\exceptions handling? It’s very, very hard to write this kind of code and very expensive. And in the end, you will not be sure on 100% in the correctness of errors handling you implemented.
- The size of an application. Well, I can’t define the upper boundary in number of code lines, when you start to suffer from the “catch them all” approach, the only thing I can say, that there are tons of good (at least not worse than other) software, which relies on “catch them all” approach, or plain error codes. I participated in a project where we chose the “catch them all” strategy; our solution consisted of over 100k lines of code and we didn’t suffer much.
So you should think at first about whether you can afford yourself the easier life, or not. The choice is up to you. There is no single right answer for all cases.
As Joe Duffy said:
…most people don’t write robust error handling code in non-systems programs, throwing an exception usually gets you out of a pickle fast. Catching and then proceeding often works too. No harm, no foul. Statistically speaking, programs “work”.
We discussed the ways of dealing with exceptions. There is one type of errors which we don’t want to represent as exceptions. I’m talking about recoverable user code errors. But before talking about this type of errors, let’s take a little step back and talk about an important concept which will help us to understand the further material.
Categories of Errors
Before going further, we need to understand what types of errors exist. Generally, there are four types of errors:
- Recoverable and unrecoverable system errors
- Recoverable and unrecoverable user code errors
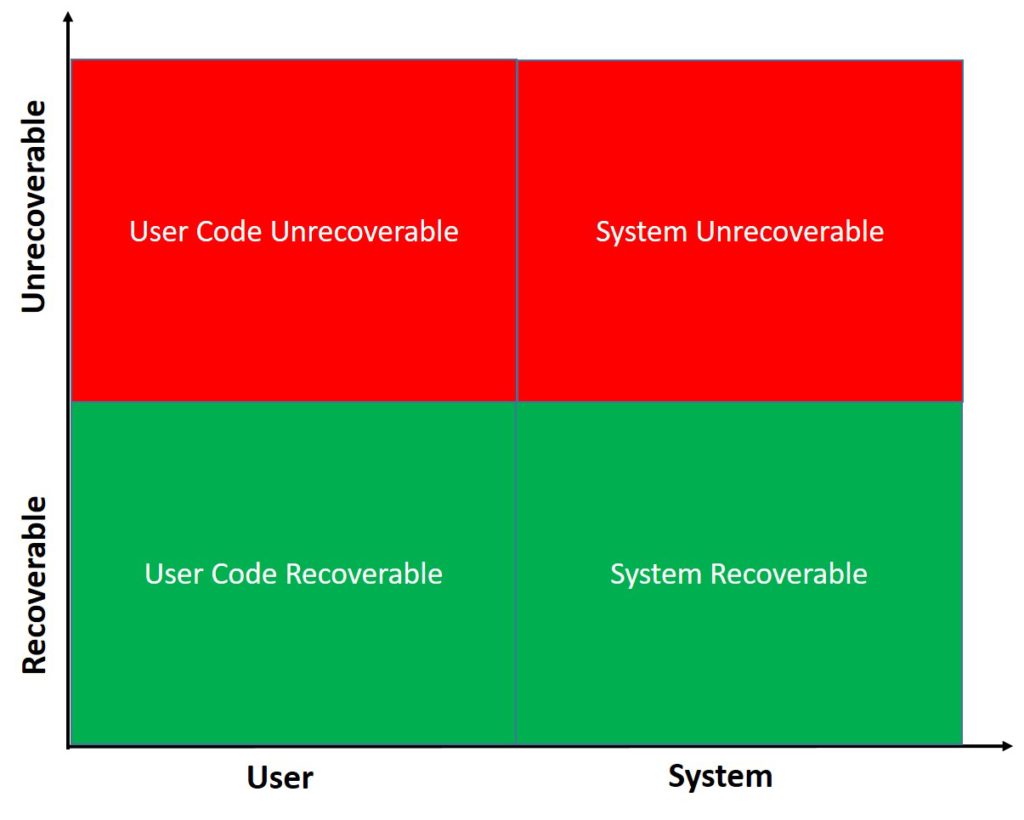
Let’s consider them in turn.
Since we use BCL extensively, we can’t evade exceptions anyway. For example, working with the file system or network, you’ll get corresponding exceptions raised by BCL logic: FileNotFoundException, SocketException, and many others. These exceptions are recoverable system errors and they should be handled. It would be ridiculous if you let these exceptions to kill your application. In such a case, our application will be crashing very often.
There are system errors which can’t be correctly handled. StackOverflowException and OutOfMemoryException belong to the class of unrecoverable system errors. Even if you want to catch them you can’t do that, CLR will just terminate your application.
You can’t eliminate exceptions we discussed so far. All you can do is to handle recoverable exceptions.
Unrecoverable user code errors are the bugs in your code, mostly. For example, invalid input into a function is a bug in the code and fairly an application should fail in such a case. NullReferenceException also signalizes a bug in your code and frankly speaking, an application also should fail in this case. We will discuss the “catch them all approach” a little bit later.
The next class of errors is “recoverable user code errors”. This type or errors represent those errors which we expect to happen, for instance when validation of business rules fails. C# books don’t make any difference between different types of errors, so they suggest to rely on exceptions in the case of recoverable user code errors as well as in any other cases. And this is horrible. Even error codes are better than exceptions when dealing with this types of errors. Though, we will not use error codes. There is a much more elegant way which we will learn a little bit later.
Remember, errors are not exceptions. An exception is a form of an error representation. The original meaning of throwing exceptions is to fail fast, unwinding the stack, until the appropriate catch block will handle the exception. The most important part here is “unwinding the stack”, this is the main difference from returning an error.
Recoverable User Code Errors
Recoverable user errors relate to a violation of domain business logic. You’ll not find a different approach to dealing with this category of errors in books on C#.
Exceptions contradict with the functional style of programming. The thing is that functions from the functional programming paradigm point of view have to be represented as mathematical functions. What it means is that a function should produce the same result for the same input and they should not produce any side effects.
Exceptions are side effects by their nature. They can’t be expressed in the method’s signature. Because of that, developers have to drill down the call stack in order to understand possible outcomes from a particular method.
Consider the following example:
[code lang=”csharp”]
public void TransferMoney(Payment p) {
ValidatePayment(p);
}
[/code]
When you stumble upon such code, you start to ask yourself whether this piece of code contains a bug or not, why the TransferMoney method doesn’t wrap a call to the ValidatePayment method intro a try-catch block? In order to understand it, you have to read the content of the ValidatePayment method. We can conclude that exceptions hide the possible bad outcome of the method’s call. The failure of any validation method belongs to the class of recoverable user errors. It means that it is exactly the case when we need to get rid of exceptions.
In order to get rid of exceptions, we need to include them into the function’s signatures. In some cases, we need to include the reason of failure, so we can’t rely on a Boolean flag anyway. Out parameters often lead to unreadable dirty code. Thus, we will introduce the Result class. Let’s look at how it looks like.
[code lang=”csharp”]
public class Result {
public bool Success { get; }
public string Error { get; private set; }
public bool Failure => !Success;
protected Result(bool success, string error) {
Success = success;
Error = error;
}
public static Result Fail(string message) {
return new Result(false, message);
}
public static Result<T> Fail<T>(string message) {
return new Result<T>(default(T), false, message);
}
public static Result Ok() {
return new Result(true, string.Empty);
}
public static Result<T> Ok<T>(T value) {
return new Result<T>(value, true, string.Empty);
}
public static Result Combine(params Result[] results) {
foreach (Result result in results) {
if (result.Failure) {
return result;
}
}
return Ok();
}
}
public class Result<T> : Result {
public T Value { get; private set; }
protected internal Result(T value, bool success, string error)
: base(success, error) {
Value = value;
}
}
[/code]
Actually, we have two Result classes here, general one and Result of T which contains the resulting object. Let’s look at the general one.
Result contains three properties:
- IsSuccess Boolean flag which returns true in the case of successful result of an operation, otherwise false;
- The Error property of type string contains the description of a failure;
- IsFailure is introduced for the sake of convenience.
Let’s look at the constructor. The constructor is protected, what deprecates the explicit creation of a result object. A little bit further you can see a bunch of static creational methods: Fail, Fail of T, Success, and Success of T. Methods with generics are used for the creation of a result object with a stored value inside.
The Result of T class just extends the Result class and brings the T-Value property for storing a result value.
Ok, before looking at how to use the Result class, let’s take a step back and look at the concept of pipelining.
Pipelining in C# by Method Chaining
Pipelining is a technique which allows an output of one function to be passed to the next one. This allows organizing the natural flow of data. At first, let’s consider a counter-example.
Consider the next code snipper:
[code lang=”csharp”]
File.WriteAllText(@"C:\tmp\Notes.txt",
Encoding.ASCII.GetString (
new byte[] {83, 80, 79, 67, 75}
)
);
[/code]
The reading order of this code is reverted from the human point of view, because in order to understand the meaning of this code you have to read it from the innermost statement to the outermost.
Sometimes, you can find yourself writing such code with 4 and 5 levels of nesting. Why we write code like this? Because we don’t want to introduce unimportant intermediate variables like in the following example:
[code lang=”csharp”]
var textInBytes = new byte[] { 83, 80, 79, 67, 75 };
var contents = Encoding.ASCII.GetString(textInBytes);
Console.WriteLine(contents);
[/code]
The previous code sample is rewritten here with intermediate variables. We don’t like such code as well as the previous one. We have here meaningless variables, we actually don’t need them.
Pipelining is a so neat and powerful technique that for example, F# has a so-called pipeline operator. The previous example would look like this in F#:
[code lang=”fsharp”]
[| 83uy; 80uy; 79uy; 67uy; 75uy |]
|> Encoding.ASCII.GetString(textInBytes)
|> Console.WriteLine(contents)
[/code]
This code can be read naturally because it goes straightforward. Unfortunately, we don’t have such an operation built in C#.
What we can do about that is to chain methods. Methods chaining is a functional-style architectural pattern which has to be supported by types since the programming language doesn’t support pipelining explicitly.
LINQ was designed bearing in mind functional concepts like pipelining. That’s why you can chain methods like Range, Where, Skip, ToList and so on. Another example of methods chaining without LINQ is the StringBuilder which was developed in such a way that you can chain appending methods.
Here is an example:
[code lang=”csharp”]
new StringBuilder()
.Append("Bla")
.AppendLine("Bla-Bla")
.AppendFormat("Formatted Bla:{0}", "bla-arg");
[/code]
This is possible because Append, AppendLine and AppendFormat methods return updated StringBuilder object instance. That’s why you can chain these methods. Let’s look at how we can chain methods on the Result class. The same approach we use in our Result class. Look at the extensions of the Result:
[code lang=”csharp”]
public static class ResultExtensions {
public static Result OnSuccess(this Result result, Func<Result> func) {
return result.Failure ? result : func();
}
public static Result OnSuccess(this Result result, Action action) {
if (result.Failure) {
return result;
}
action();
return Result.Ok();
}
public static Result OnSuccess<T>(this Result<T> result, Action<T> action) {
if (result.Failure) {
return result;
}
action(result.Value);
return Result.Ok();
}
public static Result<T> OnSuccess<T>(this Result result, Func<T> func) {
if (result.Failure) {
return Result.Fail<T>(result.Error);
}
return Result.Ok(func());
}
public static Result<T> OnSuccess<T>(this Result result, Func<Result<T>> func) {
if (result.Failure) {
return Result.Fail<T>(result.Error);
}
return func();
}
public static Result OnSuccess<T>(this Result<T> result, Func<T, Result> func) {
if (result.Failure) {
return result;
}
return func(result.Value);
}
public static Result OnFailure(this Result result, Action action) {
if (result.Failure) {
action();
}
return result;
}
public static Result OnBoth(this Result result, Action<Result> action) {
action(result);
return result;
}
public static T OnBoth<T>(this Result result, Func<Result, T> func) {
return func(result);
}
}
[/code]
Success and Failure methods return a Result instance. In order to organize the control flow, we also need to add extension methods.
Look at the extension methods we need. We need to manage the control flow in the case of success and failure. The OnSuccess extension accepts the func delegate which in its turn returns a Result instance. Let’s look at an example of using these extensions:
[code lang=”csharp”]
public Result ProcessStudent(Student student) {
return student.Enroll()
.OnFailure(() => Console.WriteLine("We need to enroll the student manually"))
.OnSuccess(() =>
student.PayGrant()
.OnFailure(() => Console.WriteLine("We need to process payment manually"))
)
.OnBoth(result => Log(result));
}
[/code]
We have a Student class which exposes two methods which can fail, so they return Result. Look at the content of the ProcessStudent method. We return here the result of a sequence of operations. Firstly, we try to enroll a student. If the operation failed we log some information to the console and return from the method the result of the Enroll method. If enroll finished successfully, then we try to pay a grant for that student. If this operation fails we log some information to the console and return the result of the PayGrant operation. If the PayGrant operation finishes successfully, then we return the successful result from the ProcessStudent method. In both scenarios, we log the result in the end of the operation.
Notice that this is a flat method with a cyclomatic complexity of one since there are no any if-statements.
The functional approach is very powerful, just try to use the Result class for handling recoverable user errors and extend existing BCL classes with extension methods when possible. Very often you can drastically simplify your code base by applying functional principles both to the overall design of your application and handling of errors.
Look at another example of a refactoring made by using the Result monad. In the next code snippet you can see a horrible method polluted with try-catch block which spans more than 40 lines:
[code lang=”csharp”]
public Result CreateCustomer(string name, string billingInfo) {
Result<BillingInfo> billingInfoResult;
try {
billingInfoResult = BillingInfo.Create(billingInfo);
}
catch (Exception ex) {
Log(ex);
return CreateResponseMessage(ex);
}
Result<CustomerName> customerNameResult;
try {
customerNameResult = CustomerName.Create(name);
}
catch (Exception ex) {
Log(ex);
return CreateResponseMessage(ex);
}
try {
_paymentGateway.ChargeCommission(billingInfoResult.Value);
}
catch (Exception ex) {
Log(ex);
return CreateResponseMessage(ex);
}
var customer = new Customer(customerNameResult.Value);
try {
_repository.Save(customer);
}
catch (Exception ex) {
Log(ex);
_paymentGateway.RollbackLastTransaction();
}
try {
_emailSender.SendGreetings(customerNameResult.Value);
}
catch (Exception ex) {
Log(ex);
return CreateResponseMessage(ex);
}
return CreateResponseMessage(true);
}
[/code]
It can be refactored into a simple method by using the Result monad. Look at the result of such a refactoring:
[code lang=”csharp”]
public Result CreateCustomer(string name, string billingInfo) {
Result<BillingInfo> billingInfoResult = BillingInfo.Create(billingInfo);
Result<CustomerName> customerNameResult = CustomerName.Create(name);
return Result.Combine(billingInfoResult, customerNameResult)
.OnSuccess(() => _paymentGateway.ChargeCommission(billingInfoResult.Value))
.OnSuccess(() => new Customer(customerNameResult.Value))
.OnSuccess(customer => _repository.Save(customer)
.OnFailure(() => _paymentGateway.RollbackLastTransaction()))
.OnSuccess(() => _emailSender.SendGreetings(customerNameResult.Value))
.OnBoth(result => Log(result));
}
[/code]
Wow, this method spans just 11 lines. This is a significant accomplishment. This method is much simpler than the previous one.
Conclusion on the Result monad
To sum up, let’s consider a bunch of method signatures.
[code lang=”csharp”]
public void EnrolStudent(Student student){} //not expected to fail (command)
public Result EnrolStudent(Student student){} //expected to fail (command)
public Student GetStudent(string name){} //not expected to fail (query)
public Result<Student> GetStudent(string name) //not expected to fail (query)
[/code]
If you rely on the Result class and functional approach, then you should explicitly state within your team the following:
- commands which return void should not fail ever
- commands which return Result may fail and a caller has to deal with it
- queries which return directly the object should not fail, they always should return an instance of the type they declared as the return type
- queries which return the Result of T may fail and a caller has to deal with it
As a side note, I want to mention the other ways of avoiding exceptions.
Tester-Doer, TryParse and Code Errors
The first way of avoding exceptions is to implement the Tester-Doer pattern. Sometimes you want to allow users of your API to avoid dealing with exceptions by providing a tester property or method. More often it’s a property.
BCL extensively uses this pattern. Here are just two examples:
ICollection.IsReadOnly boolean property and Stream.CanSeek Boolean property. They both can be used by a client to test if a collection or a stream supports specific functionality.
For example:
[code lang=”csharp”]
ICollection<Student> students = GetStudents();
//can add a student
if (!students.IsReadOnly) {
students.Add(new Student(“Joe”)); //doer
}
[/code]
You can see here that we check if a collection supports adding operations by calling to a tester property IsReadOnly. If a test passes, then we can do something by calling to a doer method. In this case the Add method.
If a common use case may potentially throw an exception, consider the option of exposing a tester property.
Keep in mind, that from the concurrency perspective this pattern is dangerous since the result returned by a tester might become invalid between the call of a tester and the doer.
Another unfortunate thing, in my opinion, is that the Tester-Doer pattern resembles the well-known anti-pattern called “temporal coupling”. If a client doesn’t know that a tester property exists and forgets to check it before calling the doer, then troubles are guaranteed.
The second way of avoiding exceptions is to rely on the TryParse pattern. Here is an example of that pattern:
[code lang=”csharp”]
DateTime birthday;
bool parsed = DateTime.TryParse("12/08/1988", out birthday);
if (parsed)
{
SocialNumber socialNumber;
parsed = SocialNumber.TryParse("1239584594", out socialNumber);
if (parsed) { }
else { }
}
else
{
}
[/code]
Do you know why this pattern came from developers mind? Because exceptions everywhere is the real headache. Eric Lippert said, that this pattern helps to overcome the problem of so-called (by Eric Lipper) “vexing” exceptions. Recall DateTime.TryParse as an example. This pattern will become more pleasant with C#7 since we will be able to omit the preliminary declaration of variables; We will be able to just remove the declaration of the “birthday” variable in the example above. Unfortunately, the problem of returning a boolean instead of high-level Result object stays unsolved.
The third way of avoiding exceptions is to use code errors. It feels like code errors are outdated, but we will never get rid of them. They often sneak in at the boundaries of applications. They come from devices, for instance. By the way, there are modern languages which rely on code errors as the main error handling mechanism, the Go language, for example. By the way, exceptions are not used in NASA’s mars rovers software. I want to stress out that generally we don’t want to use code errors in C#, there is a better with the Result monad which we discussed above.
Conclusion
- Strive to track the control flow. If it drills down to unmanaged code, be prepared for unfortunate things.
- We talked about 3 exceptions handling strategies. Choose one depending on the certain requirements of a concrete application.
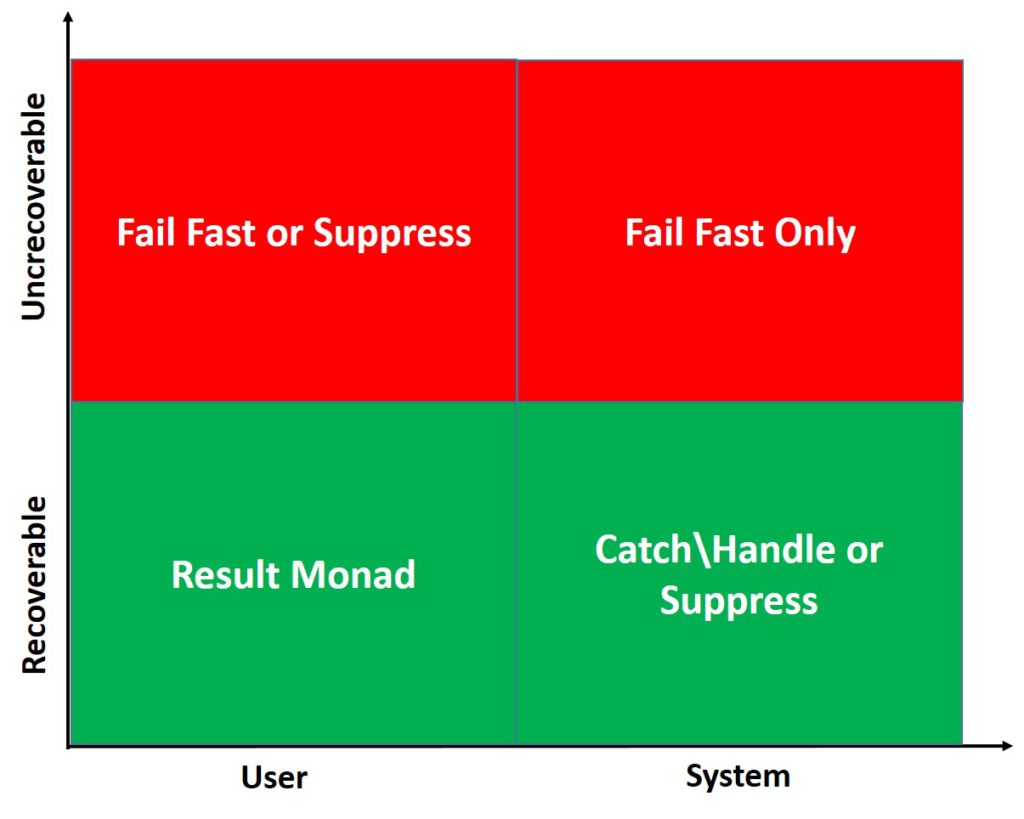
There are four categories of errors. In the case of unrecoverable user code errors you can either let an application to fail-fast or swallow them at your own risk.
An application will fail in 99% of cases if an unrecoverable system error occurred. In practice, the only way to go here is to fail-fast.
Recoverable errors have to be handled. In the case of recoverable user code errors you’d better avoid using exceptions for representing them and rely on the Result monad, rely on code errors as the last resort.
System recoverable errors also have to be handled. Sometimes handling just implies swallowing.
Actually, the Result monad is simplified in this article. You’ll find all the necessary source code here and the NuGet package here, the author is Vladimir Khorikov.
Errors Handling and many other topics you’ll find in my new video course “API in C#: The Best Practices of Design and Implementation”. Take it with 60% discount!